# JS执行机制
JS是单线程的但是依靠宿主环境浏览器又可以支持异步执行代码,同步代码与异步代码通过事件循环机制有条不紊的执行,执行每一段代码都会创建一个上下文环境,这个上下文环境中包含了定义的变量,可访问的作用域链,this指针,对于正在执行的代码会将当前上下文推入到执行栈中,执行完之后再从栈中推出后再继续执行栈中剩余的代码。
先从执行上下文开始,执行上下文包含三大要素:
变量对象
作用域
this
# 执行上下文
执行上下文 就是一段 JavaScript 代码的执行环境,在一段 JS 脚本执行之前,要先解析代码(所以说 JS 是解释执行的脚本语言),解析的时候会先创建一个执行上下文环境,先把代码中即将执行的变量、函数声明都拿出来。变量先暂时赋值为undefined,函数则先声明好可使用。这一步做完了,然后再开始正式执行程序。
有三种类型的代码会创建一新的执行上下文
运行代码主体的全局上下文,也就是说它是为那些存在于JavaScript 函数之外的任何代码而创建的。
运行函数内代码的局部上下文,每个函数会在执行代码的时候创建自己的执行上下文,即局部上下文
使用
eval()函数也会创建一个新的执行上下文
每一个上下文在本质上都是一种作用域层级。每个代码段开始执行的时候都会创建一个新的上下文栈来运行它,并且在代码退出的时候销毁掉
# 执行上下文的生命周期
执行上下文的生命周期包括三个阶段:创建阶段 -> 执行阶段 -> 回收阶段
创建阶段
当函数被调用,但未执行任何其内部代码之前,会做以下三件事:
创建变量对象:提升函数声明和变量声明,如果是函数还需要初始化参数
arguments创建作用域链(Scope Chain):在上下文的创建阶段,作用域链是在变量对象之后创建的。作用域链用于解析变量。当被要求解析变量时,JavaScript 始终从代码嵌套的最内层开始,如果最内层没有找到变量,就会跳转到上一层父作用域中查找,直到找到该变量。
确定this指向:包括多种情况,下文会详细说明
执行阶段
执行变量赋值、代码执行
回收阶段
执行上下文出栈等待虚拟机回收执行上下文
活动的执行上下文在逻辑上组成一个堆栈。堆栈底部永远都是全局上下文(global context),而顶部就是当前(活动的)执行上下文。堆栈在EC类型进入和退出上下文的时候被修改(推入或弹出)
例如,我们可以定义执行上下文堆栈是一个数组:
ECStack = []
每次进入function (即使function被递归调用或作为构造函数) 的时候或者内置的eval函数工作的时候,这个堆栈都会被压入
全局代码
这种类型的代码是在"程序"级处理的:例如加载外部的js文件或者本地<script></script>标签内的代码。全局代码不包括任何function体内的代码
在初始化(程序启动)阶段,ECStack是这样的:
ECStack = [
globalContext
];
函数代码
当进入funtion函数代码(所有类型的funtions)的时候,ECStack被压入新元素。需要注意的是,具体的函数代码不包括内部函数(inner functions)代码。如下所示,我们使函数自己调自己的方式递归一次:
(function foo(bar) {
if (bar) {
return;
}
foo(true);
})();
那么,ECStack以如下方式被改变:
// 第一次foo的激活调用
ECStack = [
<foo> functionContext
globalContext
];
// foo的递归激活调用
ECStack = [
<foo> functionContext – recursively
<foo> functionContext
globalContext
];
每次return的时候,当前执行上下文也就从ECStack弹出,一个抛出的异常如果没被截获的话也有可能从一个或多个执行上下文退出。相关代码执行完以后,ECStack只会包含全局上下文(global context),一直到整个应用程序结束
let outputElem = document.getElementById("output");
let userLanguages = {
"Mike": "en",
"Teresa": "es"
};
function greetUser(user) {
function localGreeting(user) {
let greeting;
let language = userLanguages[user];
switch(language) {
case "es":
greeting = `¡Hola, ${user}!`;
break;
case "en":
default:
greeting = `Hello, ${user}!`;
break;
}
return greeting;
}
outputElem.innerHTML += localGreeting(user) + "<br>\r";
}
greetUser("Mike");
greetUser("Teresa");
greetUser("Veronica");
程序开始运行时,全局上下文就会被创建好
当执行到
greetUser("Mike")的时候会为greetUser()函数创建一个它的上下文。这个执行上下文会被推入执行上下文栈中当
greetUser()调用localGreeting()的时候会为该方法创建一个新的上下文当
localGreeting()函数执行完之后就会将它的上下文从执行栈中弹出并销毁。程序会从栈中获取下一个上下文并恢复执行, 也就是从greetUser()剩下的部分开始执行
当
greetUser()执行完毕后,其上下文也从执行栈中弹出并销毁之后执行
greetUser("Teresa")和greetUser("Veronica")方法的时候,也是同上面的步骤
主程序退出,全局执行上下文从执行栈中弹出。此时栈中所有的上下文都已经弹出,程序执行完毕
递归函数及其上下文
关于递归函数——即多次调用自身的函数,需要特别注意:每次递归调用自身都会创建一个新的上下文。这使得 JavaScript 运行时能够追踪递归的层级以及从递归中得到的返回值,但这也意味着每次递归都会消耗内存来创建新的上下文
# 变量对象
变量对象(缩写为VO)是一个与执行上下文相关的特殊对象(抽象概念),它存储着当前上下文中的以下内容:
变量 (var, 变量声明);
函数声明 (FunctionDeclaration, 缩写为FD);
函数的形参
以下是使用JS对象的形式来表示一个上下文中的VO
activeExecutionContext = {
VO: {
// 上下文数据(var, FD, function arguments)
}
};
假设现在有以下代码:
var a = 10;
function test(x) {
var b = 20;
};
test(30)
对应的变量对象是:
// 全局上下文的变量对象
VO(globalContext) = {
a: 10,
test: <reference to function>
};
// test函数上下文的变量对象
VO(test functionContext) = {
x: 30,
b: 20
};
只有全局上下文的变量对象允许通过VO的属性名称来间接访问(因为在全局上下文里,全局对象自身就是变量对象,稍后会详细介绍),在其它上下文中是不能直接访问VO对象的,因为它只是内部机制的一个实现
# 不同上下文中的变量对象
执行上下文可分全局上下文和局部上下文(函数上下文),在不同类型的上下文中,变量对象是有差异的
全局上下文中的变量对象
全局对象(Global object) 是在进入任何执行上下文之前就已经创建了的对象
这个对象只存在一份,它的属性在程序中任何地方都可以访问,全局对象的生命周期终止于程序退出那一刻
全局对象初始创建阶段将Math、String、Date、parseInt等作为自身属性,初始化之后也可以用额外创建的其它对象作为属性(这个属性也可以指向到全局对象自身)。例如在 DOM 中,全局对象的window属性就可以引用全局对象自身
global = {
Math: <...>,
String: <...>
...
...
window: global //引用自身
};
回到全局上下文中的变量对象——在这里,变量对象就是全局对象自己:
VO(globalContext) === global;
基于这个原理,在全局上下文中声明的对象,我们才可以间接通过全局对象的属性来访问它
var a = new String('test');
alert(a); // 直接访问,在VO(globalContext)里找到:"test"
alert(window['a']); // 间接通过global访问:global === VO(globalContext): "test"
alert(a === this.a); // true
var aKey = 'a';
alert(window[aKey]); // 间接通过动态属性名称访问:"test"
函数上下文中的变量对象
在函数执行上下文中,VO 是不能直接访问的,此时由活动对象(activation object,缩写为AO)扮演VO的角色
VO(functionContext) === AO
活动对象是在进入函数上下文时刻被创建的,它通过函数的arguments属性初始化。arguments属性的值是Arguments对象:
AO = {
arguments: <ArgO>
};
Arguments对象是活动对象的一个属性,它包括如下属性:
callee— 指向当前函数的引用length— 真正传递的参数个数properties-indexes(字符串类型的整数) 属性的值就是函数的参数值(按参数列表从左到右排列)
# 变量对象的初始化&&变量提升
在处理执行上下文的时候基本有两个阶段
进入执行上下文
执行代码
变量对象的修改变化与这两个阶段紧密相关
进入执行上下文阶段
当进入执行上下文(代码执行之前)时,VO里已经包含了下列属性
函数的所有形参(如果我们是在函数执行上下文中)
[参数名]:[参数值], 如果没有传递对应参数的话,那么由名称和undefined值组成的一种变量对象的属性也将被创建
所有函数声明(FunctionDeclaration, FD)
[参数名]:[参数值], 如果变量对象已经存在相同名称的属性,则完全替换这个属性
所有变量声明(var, VariableDeclaration)
[参数名]:[参数值], 如果变量名称跟已经声明的形式参数或函数相同,则变量声明不会干扰已经存在的这类属性
让我们看一个例子:
function test(a, b) {
var c = 10;
function d() {}
var e = function _e() {};
(function x() {});
}
test(10); // call
当进入带有参数10的test函数上下文时,AO表现为如下:
AO(test) = {
a: 10,
b: undefined,
c: undefined,
d: <reference to FunctionDeclaration "d">
e: undefined
}
AO里并不包含函数x。这是因为x 是一个函数表达式(FunctionExpression, 缩写为 FE) 而不是函数声明,函数表达式不会影响VO。 不管怎样,函数_e 同样也是函数表达式,但是就像我们下面将看到的那样,因为它分配给了变量 e,所以它可以通过名称e来访问。 函数声明FunctionDeclaration与函数表达式FunctionExpression 的不同
这之后,将进入处理上下文代码的第二个阶段 — 执行代码。
执行代码
这个周期内,AO/VO已经拥有了属性(不过,并不是所有的属性都有值,大部分属性的值还是系统默认的初始值undefined )
还是前面那个例子, AO/VO在代码解释期间被修改如下:
AO['c'] = 10;
AO['e'] = <reference to FunctionExpression "_e">
再次注意,因为FunctionExpression _e保存到了已声明的变量e上,所以它仍然存在于内存中。而FunctionExpression x却不存在于AO/VO中,也就是说如果我们想尝试调用 x 函数,不管在函数定义之前还是之后,都会出现一个错误x is not defined,未保存的函数表达式只有在它自己的定义或递归中才能被调用
另一个经典例子:
alert(x); // function
var x = 10;
alert(x); // 10
x = 20;
function x() {};
alert(x); // 20
为什么第一个alert(x) 的返回值是function,而且它还是在x 声明之前访问的x 的?为什么不是10或20呢?因为,根据规范函数声明是在进入上下文时填入的 ,同一周期,在进入上下文的时候还有一个变量声明x,那么正如我们在上一个阶段所说,变量声明在顺序上跟在函数声明和形式参数声明之后,而且在这个进入上下文阶段,变量声明不会干扰VO中已经存在的同名函数声明或形式参数声明,因此,在进入上下文时,VO的结构如下:
VO = {};
VO['x'] = <reference to FunctionDeclaration "x">
// 找到var x = 10;
// 如果function "x"没有已经声明的话
// 这时候"x"的值应该是undefined
// 但是这个case里变量声明没有影响同名的function的值
VO['x'] = <the value is not disturbed, still function>
紧接着,在执行代码阶段,VO做如下修改:
VO['x'] = 10;
VO['x'] = 20;
再来一个例子:
if (true) {
var a = 1;
} else {
var b = 2;
}
alert(a); // 1
alert(b); // undefined,不是b没有声明,而是b的值是undefined
在下面的例子里我们可以再次看到,变量是在进入上下文阶段放入VO中的。(因为,虽然else部分代码永远不会执行,但是不管怎样,变量b仍然存在于VO中)
# 变量提升
上文也提到了,变量提升是发生在进入执行上文阶段,需要注意的点有两个:
如果存在函数声明,则这个变量名的初始值就是这个函数,无论在函数声明之前是否有同名的
var变量或者是同名的参数对于
var声明的变量,不会覆盖这个变量之前的同名变量,如果没有同名的变量会隐式声明一个值为undefined的同名变量
function fn(name){
console.log(name) // "function name(){console.log()}"
function name(){}
function name(){console.log()}
var name = 110
console.log(name) // 110
}
fn('lanjz')
// -----------------
function fn(){
console.log(name) // "undefined"
var name = 110
}
fn()
// ---------------
function fn(name){
console.log(name) // "lanjz"
var name = 110
}
fn('lanjz')
# 关于变量
通常,各类文章和JavaScript相关的书籍都声称:“不管是使用var关键字(在全局上下文)还是不使用var关键字(在任何地方),都可以声明一个变量”。请记住,这是错误的概念:
任何时候,变量只能通过使用var关键字才能声明。
赋值语句:a = 10;,这仅仅是给全局对象创建了一个新属性(但它不是变量),“不是变量”并不是说它不能被改变,而是指它不符合ECMAScript规范中的变量概念
它之所以能成为全局对象的属性,完全是因为VO(globalContext) === global
让我们通过下面的实例看看具体的区别吧:
alert(a); // undefined
alert(b); // "b" 没有声明
b = 10;
var a = 20;
所有根源仍然是VO和进入上下文阶段和代码执行阶段:
进入上下文阶段:
VO = {
a: undefined
};
我们可以看到,因为“b”不是一个变量,所以在这个阶段根本就没有“b”,“b”将只在代码执行阶段才会出现(但是在我们这个例子里,还没有到那就已经出错了)。
让我们改变一下例子代码:
alert(a); // undefined, 这个大家都知道,
b = 10;
alert(b); // 10, 代码执行阶段创建
var a = 20;
alert(a); // 20, 代码执行阶段修改
关于变量,还有一个重要的知识点。变量相对于简单属性来说,变量有一个特性(attribute):{DontDelete},这个特性的含义就是不能用delete操作符直接删除变量属性
a = 10;
alert(window.a); // 10
alert(delete a); // true
alert(window.a); // undefined
var b = 20;
alert(window.b); // 20
alert(delete b); // false
alert(window.b); // still 20
但是这个规则在有个上下文里不起走样,那就是eval上下文,变量没有{DontDelete}特性
eval('var a = 10;');
alert(window.a); // 10
alert(delete a); // true
alert(window.a); // undefined
深入理解JavaScript系列(12):变量对象(Variable Object) (opens new window)
# 作用域
当要执行主代码或者函数的时候,会为其创建执行上下文,每个上下文中有自己的变量对象:对于全局上下文,它是全局变量对象自身;对于函数,它是活动对象
var x = 10;
function foo() {
var y = 20;
function bar() {
alert(x + y);
}
return bar;
}
foo()(); // 30
上面的变量对象有:全局变量对象VO(global),foo函数活动对象AO(foo),bar函数活动对象AO(bar)
作用域链正是内部上下文所有变量对象(包括父变量对象)的列表。此链用来变量查询。即在上面的例子中,bar上下文的作用域链包括AO(bar)、AO(foo)和VO(global)
当查找变量的时候,会先从当前上下文的变量对象中查找,如果没有找到,就会从父级执行上下文的变量对象中查找,一直找到全局上下文的变量对象,也就是全局对象。这样由多个执行上下文的变量对象构成的链表就叫做作用域链
作用域链在上下文初始阶段创建的,包含活动对象和这个函数内部的[[scope]]属性。下面我们将更详细的讨论一个函数的[[scope]]属性
activeExecutionContext = {
VO: {...}, // or AO
this: thisValue,
Scope: [ // Scope chain
// 所有变量对象的列表
// for identifiers lookup
]
};
上面代码上的其scope定义如下:
Scope = AO + [[Scope]]
上面的[[scope]]是所有父变量对象的层级链,处于当前函数上下文之上,在函数创建时存于其中
下面通过具体的函数声明到执行来进一步了解Scope
# 函数生命周期和Scope
函数调用的上下文生命周期分为创建和激活阶段(调用时)
函数创建
var x = 10;
function foo() {
var y = 20;
alert(x + y);
}
foo(); // 30
当调用foo()时,创建上下文时会为其创建AO对象,作用域和this,这时先不讨论this,那么此时foo的AO如下:
fooContext.AO = {
y: undefined, // undefined
[[Scope]]: [
globalContext.VO // === Global
]
};
父作用域[[Scope]]的值:
foo.[[Scope]] = [
globalContext.VO // === Global
];
那么整个作用域scope就为:Scope = AO|VO + [[Scope]]
函数激活
当函数激活时,寻找变量时就会从作用中查找,先从当前AO中查找,如果没有话再从父作用域[[Scope]]中查找,直到最顶端
我们用一个稍微复杂的例子描述上面讲到的这些
var x = 10;
function foo() {
var y = 20;
function bar() {
var z = 30;
alert(x + y + z);
}
bar();
}
foo(); // 60
分析一下上面例子的变量/活动对象,函数的的[[scope]]属性以及上下文的作用域链:
首先全局上下文的变量对象是:
globalContext.VO === Global = {
x: 10
foo: <reference to function>
};
在foo创建时,foo的[[scope]]属性是:
foo.[[Scope]] = [
globalContext.VO
]
在foo激活时(进入上下文),foo上下文的活动对象是:
fooContext.AO = {
y: 20,
bar: <reference to function>
}
foo上下文的作用域链为:
fooContext.Scope = fooContext.AO + foo.[[Scope]] // i.e.:
fooContext.Scope = [
fooContext.AO,
globalContext.VO
];
内部函数bar创建时,其[[scope]]为:
bar.[[Scope]] = [
fooContext.AO,
globalContext.VO
];
在bar激活时,bar上下文的活动对象为:
barContext.AO = {
z: 30
}
bar上下文的作用域链为:
barContext.Scope = barContext.AO + bar.[[Scope]] // i.e.:
barContext.Scope = [
barContext.AO,
fooContext.AO,
globalContext.VO
]
对x、y、z的标识符解析如下:
- barContext.AO // not found
-- fooContext.AO // not found
-- globalContext.VO // found - 10
- "y"
-- barContext.AO // not found
-- fooContext.AO // found - 20
- "z"
-- barContext.AO // found - 30
# 作用域特征
[[scope]]是所有父变量对象的层级链,处于当前函数上下文之上,在函数创建时存于其中。
注意这重要的一点--[[scope]]在函数创建时被存储--静态(不变的),永远永远,直至函数销毁。即:函数可以永不调用,但[[scope]]属性已经写入,并存储在函数对象中
var x = 10;
function foo() {
alert(x);
}
(function () {
var x = 20;
foo(); // 10, but not 20
})();
函数创建时定义的词法作用域--变量解析为10,而不是30
通过构造函数创建的函数的[[scope]]
在上面的例子中,我们看到,在函数创建时获得函数的[[scope]]属性,通过该属性访问到所有父上下文的变量。但是,这个规则有一个重要的例外,它涉及到通过函数构造函数创建的函数
var x = 10;
function foo() {
var y = 20;
function barFD() { // 函数声明
alert(x);
alert(y);
}
var barFE = function () { // 函数表达式
alert(x);
alert(y);
};
var barFn = Function('alert(x); alert(y);');
barFD(); // 10, 20
barFE(); // 10, 20
barFn(); // 10, "y" is not defined
}
foo();
我们看到,通过函数构造函数(Function constructor)创建的函数bar,是不能访问变量y的。但这并不意味着函数barFn没有[[scope]]属性(否则它不能访问到变量x)。问题在于通过函构造函数创建的函数的[[scope]]属性总是唯一的全局对象。考虑到这一点,如通过这种函数创建除全局之外的最上层的上下文闭包是不可能的
二维作用域链查找
在作用域链中查找最重要的一点是变量对象的属性(如果有的话)须考虑其中--源于ECMAScript 的原型特性,如果一个属性在对象中没有直接找到,查询将在原型链中继续。即常说的二维链查找。(1)作用域链环节;(2)每个作用域链--深入到原型链环节。如果在Object.prototype中定义了属性,我们能看到这种效果
function foo() {
alert(x);
}
Object.prototype.x = 10;
foo(); // 10
活动对象没有原型,我们可以在下面的例子中看到
function foo() {
var x = 20;
function bar() {
alert(x);
}
bar();
}
Object.prototype.x = 10;
foo(); // 20
上面例子中如果函数bar上下文的AO有一个原型,那么x将在Object.prototype 中被解析,那么将输出10
# 代码执行时对作用域链的影响
在ECMAScript 中,在代码执行阶段有两个声明能修改作用域链。这就是with声明和catch语句。它们添加到作用域链的最前端,对象须在这些声明中出现的标识符中查找。如果发生其中的一个,作用域链简要的作如下修改:
var foo = {x: 10, y: 20};
with (foo) {
alert(x); // 10
alert(y); // 20
}
作用域链修改成这样:
Scope = foo + AO|VO + [[Scope]]
var x = 10, y = 10;
with ({x: 20}) {
var x = 30, y = 30;
alert(x); // 30
alert(y); // 30
}
alert(x); // 10
alert(y); // 30
在进入上下文时发生了什么?标识符x和y已被添加到变量对象中。此外,在代码运行阶段作如下修改:
x = 10, y = 10;
对象
{x:20}添加到作用域的前端在
with内部,遇到了var声明,当然什么也没创建,因为在进入上下文时,所有变量已被解析添加在第二步中,仅修改变量
x,实际上对象中的x现在被解析,并添加到作用域链的最前端,x为20,变为30同样也有变量对象
y的修改,被解析后其值也相应的由10变为30此外,在
with声明完成后,它的特定对象从作用域链中移除(已改变的变量x--30也从那个对象中移除),即作用域链的结构恢复到with得到加强以前的状态在最后两个
alert中,当前变量对象的x保持同一,y的值现在等于30,在with声明运行中已发生改变。
同样,catch语句的异常参数变得可以访问,它创建了只有一个属性的新对象--异常参数名。图示看起来像这样:
try {
...
} catch (ex) {
alert(ex);
}
作用域链修改为:
var catchObject = {
ex: <exception object>
};
Scope = catchObject + AO|VO + [[Scope]]
在catch语句完成运行之后,作用域链恢复到以前的状态
# 闭包
函数可以作为参数传递给其他函数使用 (在这种情况下,函数被称为“funargs”——“functional arguments”)。接收funargs的函数被称之为 高阶函数(higher-order functions) 。其他函数的运行时也会返回函数,这些返回的函数被称为 function valued 函数 (有 functional value 的函数)
闭包的作用域问题:
当一个函数从其他函数返回到外部的时候,当函数被激活时,上下文的作用域链表现为激活对象与[[Scope]]属性的组合
Scope chain = Activation object + [[Scope]]
作用域链 = 活动对象 + [[Scope]]
EMCAScript使用静态作用域,即作用域是在函数创建产生,且不会被改变
function foo() {
var x = 10;
return function bar() {
console.log(x);
};
}
// "foo"返回的也是一个function
// 并且这个返回的function可以随意使用内部的变量x
var returnedFunction = foo();
// 全局变量 "x"
var x = 20;
// 支持返回的function
returnedFunction(); // 结果是10而不是20
// 全局变量 "x"
var x = 10;
// 全局function
function foo() {
console.log(x);
}
(function (funArg) {
// 局部变量 "x"
var x = 20;
// 这不会有歧义
// 因为我们使用"foo"函数的[[Scope]]里保存的全局变量"x",
// 并不是caller作用域的"x"
funArg(); // 10, 而不是20
})(foo); // 将foo作为一个"funarg"传递下去
还有一个很重要的点,几个函数可能含有相同的父级作用域(这是一个很普遍的情况,例如有好几个内部或者全局的函数)。在这种情况下,在[[Scope]]中存在的变量是会共享的。一个闭包中变量的变化,也会影响另一个闭包的
function baz() {
var x = 1;
return {
foo: function foo() { return ++x; },
bar: function bar() { return --x; }
};
}
var closures = baz();
console.log(
closures.foo(), // 2
closures.bar() // 1
);
在某个循环中创建多个函数时,上图会引发一个困惑。如果在创建的函数中使用循环变量(如”k”),那么所有的函数都使用同样的循环变量,导致一些程序员经常会得不到预期值。现在清楚为什么会产生如此问题了——因为所有函数共享同一个[[Scope]],其中循环变量为最后一次赋值
var data = [];
for (var k = 0; k < 3; k++) {
data[k] = function () {
alert(k);
};
}
data[0](); // 3, but not 0
data[1](); // 3, but not 1
data[2](); // 3, but not 2
有一些用以解决这类问题的技术。其中一种技巧是在作用域链中提供一个额外的对象,比如增加一个函数:
var data = [];
for (var k = 0; k < 3; k++) {
data[k] = (function (x) {
return function () {
alert(x);
};
})(k); // 将k当做参数传递进去
}
// 结果正确
data[0](); // 0
data[1](); // 1
data[2](); // 2
回想一下上文提到的作用域是在函数创建时被存储的--静态(不变的),根据这点就可以很好得理解闭包所包含的作用域的特性
# this
this是执行上下文中的一个属性而不是某个变量对象的属性
activeExecutionContext = {
VO: {...},
this: thisValue
};
this与上下文中可执行代码的类型有直接关系,this值在进入上下文时确定,并且在上下文运行期间永久不变
# 全局代码中的this
在全局代码中,this始终是全局对象本身,这样就有可能间接的引用到它了
# 函数代码中的this
函数代码中的this不是静态绑定到一个函数,因为this是进入上下文中的确定的,
var foo = {x: 10};
var bar = {
x: 20,
test: function () {
alert(this === bar);
alert(this.x);
// this = foo; // 错误,任何时候不能改变this的值
}
};
// 在进入上下文的时候
// this被当成bar对象
bar.test(); // true, 20
foo.test = bar.test;
foo.test(); // false, 10
this指向
在通常的函数调用中,this是由激活上下文代码的调用者来提供的,即调用函数的父上下文(parent context )。this取决于调用函数的方式
var foo = {
bar: function () {
alert(this);
alert(this === foo);
}
};
foo.bar(); // foo, true
var exampleFunc = foo.bar;
alert(exampleFunc === foo.bar); // true
// 再一次,同一个function的不同的调用表达式,this是不同的
exampleFunc(); // global, false
即使是正常的全局函数也会被调用方式的不同形式激活,这些不同的调用方式导致this值也不同。
function foo() {
alert(this);
}
foo(); // global
alert(foo === foo.prototype.constructor); // true
// 但是同一个function的不同的调用表达式,this是不同的
foo.prototype.constructor(); // foo.prototype
一个函数上下文中确定this值的通用规则如下:
一个函数上下文中,this由调用者提供,由调用函数的方式来决定。如果调用括号()的左边是引用类型的值,this将设为引用类型值的所属对象,在其他情况下(与引用类型不同的任何其它属性),这个值为全局
var foo = {
bar: function () {
alert(this);
}
};
foo.bar(); // foo
(foo.bar)(); // foo
(foo.bar = foo.bar)(); // window
(false || foo.bar)(); // window
(foo.bar, foo.bar)(); // window
第一个例子很明显———明显的引用类型,结果
this指向foo在第二个例子中,括号中仍是一个引用类型。所以
this值还是指向foo第三个例子中,括号中的赋值运算符执行之后返回的结果是函数对象(但不是引用类型),这意味着
this指向全局第四个和第五个也是一样——逗号运算符和逻辑运算符(OR)失去了引用而得到了函数,
this指向全局
this指向总结:
this总是指向直接调用它的对象,如果没有对象调用则指向全局window对于构造函数来说(
new命令),this指向的是构造函数实例对象this是不能通过=运算符直接修改的,但可以使用call,apply,bind可以改变函数this指向对于箭头函数来说,
this继承箭头函数外层的函数,如果没有外层函数则指向全局window
# 事件循环
事件循环负责不断得收集事件任务(包括用户事件以及其他非用户事件等),然后对任务进行排队并在合适的时候执行这些事件回调
根据规范,事件循环是通过任务队列的机制来进行协调的。一个 Event Loop 中,可以有一个或者多个任务队列(task queue),一个任务队列便是一系列有序任务(task)的集合;每个任务都有一个任务源(task source),源自同一个任务源的 task 必须放到同一个任务队列,从不同源来的则被添加到不同队列。
setTimeout/Promise 等API便是任务源,而进入任务队列的是他们指定的具体执行任务
在一次循环中始终以一个宏任务开始(如果有的话),待执行上下文栈为空时将执行微任务队列中的任务,待任务队列中的任务清空后,将进入渲染进程,经历渲染步骤之后,一个事件循环结束,然后继续下一次循环
macrotask->microtast->渲染->macrotask->microtast->渲染->...
这就可以解释平时工作中为了让某段代码能正确访问到 DOM,然后故意放在setTimeout中执行,目的就是为了先完成 DOM 渲染
# Tick
在事件循环中,每进行一次循环操作称为 tick,每一次 tick的任务处理模型是比较复杂的,但关键步骤如下:
执行一个宏任务(执行栈中没有就从事件队列中获取)
执行过程中如果遇到异步任务并不会一直等待其返回结果,而是会将这个事件挂起,继续执行执行栈中的其他任务
- 异步导任务完成后,异步的结果将添加到任务队列
主线程处于闲置状态时,主线程会去查找任务队列是否有任务。如果有,那么主线程会从中取出排在第一位的事件, 并把这个事件对应的回调放入执行栈中(依次执行)
当前宏任务执行完毕,开始检查渲染,然后GUI线程接管渲染
渲染完毕后,JS线程继续接管,开始下一个宏任务(从事件队列中获取)
流程图如下:
# 任务源
事件循环收集到的事件任务分两种,放入宏任务列中的是宏任务,放入到微任务队列当中是微任务
属于宏任务(macrotask)的任务源有:
script标签内的代码整体代码
setTimeout,setInterval,setImmediate(服务端 API)I/O(服务端 API)可拓展至 Web API
DOM 操作
网络任务
Ajax 请求
history traversalhistory.back()用户交互
requestAnimationFrame
其中包括常见
DOM2(addEventListener)和DOM0(onHandle)级事件监听回调函数。如click事件回调函数等
事件需要冒泡到 document 对象之后并且事件回调执行完成后,才算该宏任务执行完成
UI
rendering
属于微任务(microtask)的任务源有
process.nextTick(Node.js)Promise原型方法(即then、catch、finally)中被调用的回调函数使用
queueMicrotask()方法创建方法queueMicrotask(fn1) function fn1(){} // fn1将会放在微任务队列中MutationObserver(一个可以监听DOM结构变化的接口)用于监听节点是否发生变化
Object.observe(已废弃)
特别注明:在 ECMAScript 中称 microtask 为 jobs
宏任务 vs 微任务
事件循环首次执行的就是宏任务,且一个宠任务结束到下一个宏任务执行前会做两个事情
如果微任务队列有任务,则执行队列中的微任务
如果微任务队列中没有任务或者所有微任务执行完成,则进行DOM渲染
然后执行下一个宏任务
当执行微任务队列中的任务时,只有微任务队列执行完了才退中微任务的执行,包括中途有微任务加入。换句话说,微任务可以添加新的微任务到队列中,并在下一个任务开始执行之前且当前事件循环结束之前执行完所有的微任务
示例:
// script
// 1
console.log('I am from script beginning')
// 2
setTimeout(() => {
// 该匿名函数称为匿名函数a
console.log('I am from setTimeout')
}, 1000)
// 3
const ins = new Promise((resolve, reject) => {
console.log('I am from internal part')
resolve()
})
// 4
ins
.then(() => console.log('I am from 1st ins.then()'))
.then(() => console.log('I am from 2nd ins.then()'))
// 5
console.log('I am from script bottom')
以上整个代码段即是宏任务,它的任务源是 script
整个代码段
script进入执行上下文栈(亦称调用栈),执行 1 处代码调用console.log函数,该函数进入调用栈,之前script执行上下文执行暂停(冻结),转交执行权给console.log。console.log成为当前执行栈中的活动执行上下文(running execution context)。console.log执行完成立即弹出调用栈,script恢复执行setTimeout是一个任务分发器,该函数本身会立即执行,延迟执行的是其中传入的参数(匿名函数a)。script暂停执行,内部建立一个 1 秒计时器。script恢复执行接下来的代码。1 秒后,再将匿名函数a插入宏任务队列(根据宏任务队列是否有之前加入的宏任务,可能不会立即执行)声明变量
ins,并初始化为Promise实例。需要注意的Promise内部代码是同步的意味着会在本轮事件循环立即执行。那么此时,script冻结,开始执行console.log,console.log执行结束后弹出调用栈,resolve()进入调用栈,将Promise状态resolved,并之后弹出调用栈,此时恢复script执行因为上面完成了
resolved,将调用ins的then方法,将第一个then中回调添加到 微任务队列,继续执行,将第二个then中回调添加到 微任务队列恢复
script执行后将console.log('I am from script bottom')压入栈,执行完后弹出,继续恢复script执行script宏任务执行完成,弹出执行上下文栈。此时,微任务队列中有两个then加入的回调函数等待执行。另外,若距 2 超过 1 秒钟,那么宏任务队列中有一个匿名函数a等待执行,否则,此时宏任务队列为空在当前宏任务执行完成并弹出调用栈后,开始清空因宏任务执行而产生的微任务队列。首先执行
console.log('I am from 1st ins.then()'),之后执行console.log('I am from 2nd ins.then()')微任务队列清空后,开始调用下一宏任务(即进入下一个事件循环)或等待下一宏任务加入任务队列。此时,在 2 中如果计时超过 1 秒后,将匿名函数
a加入至宏任务队列,此时,因之前宏任务script执行完成而清空,那么将匿名函数a加入调用栈执行,输出I am from setTimeout
输出结果:
I am from script beginning
I am from internal part
I am from script bottom
I am from 1st ins.then()
I am from 2nd ins.then()
I am from setTimeout
示例总结:
在一个代码段(或理解为一个模块)中,所有的代码都是基于一个
script宏任务进行的在当前宏任务执行完成后,必须要清空因执行宏任务而产生的微任务队列
只有当前微任务队列清空后,才会调用下一个宏任务队列中的任务。即进入下一个事件循环
new Promise时,Promise参数中的匿名函数是立即执行的。被添加进微任务队列的是then中的回调函数setTimeout是作为任务分发器的存在,他自身执行会创建一个计时器,只有待计时器结束后,才会将setTimeout中的第一参数函数添加至宏任务队列。换一种方式理解,setTimeout中的函数一定不是在当前事件循环中被调用

# Q&A
为什么 setTimeout,HTTP请求,事件等是可以异步的
JS是单线程的,但是浏览器是多进程,多线程的,这些异步任务其实是交由给这浏览器其它线程处理的
定时触发器线程: 处理定时计数器,
setTimeout或setInterval事件触发线程: 一个事件被触发时该线程会把事件添加到待处理队列的队尾,等待JS引擎的处理
http请求线程: 在XMLHttpRequest在连接后是通过浏览器新开一个线程请求
await后是宏任务还是微任务
于因为async await 本身就是promise+generator的语法糖。所以await后面的代码是microtask
async function async1() {
console.log('async1 start');
await async2();
console.log('async1 end');
}
等价于
async function async1() {
console.log('async1 start');
Promise.resolve(async2()).then(() => {
console.log('async1 end');
})
}
写出这段代码输出顺序
//请写出输出内容
async function async1() {
console.log('async1 start');
await async2();
console.log('async1 end');
}
async function async2() {
console.log('async2');
}
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0)
async1();
new Promise(function(resolve) {
console.log('promise1');
resolve();
}).then(function() {
console.log('promise2');
});
console.log('script end');
// script start
// async1 start
// async2
// promise1
// script end
// async1 end
// promise2
// setTimeout
过程解析:
以上就本道题涉及到的所有相关知识点了,下面我们再回到这道题来一步一步看看怎么回事儿。
首先,事件循环从宏任务(macrotask)队列开始,这个时候,宏任务队列中,只有一个script(整体代码)任务;当遇到任务源(task source)时,则会先分发任务到对应的任务队列中去。所以,上面例子的第一步执行如下图所示:
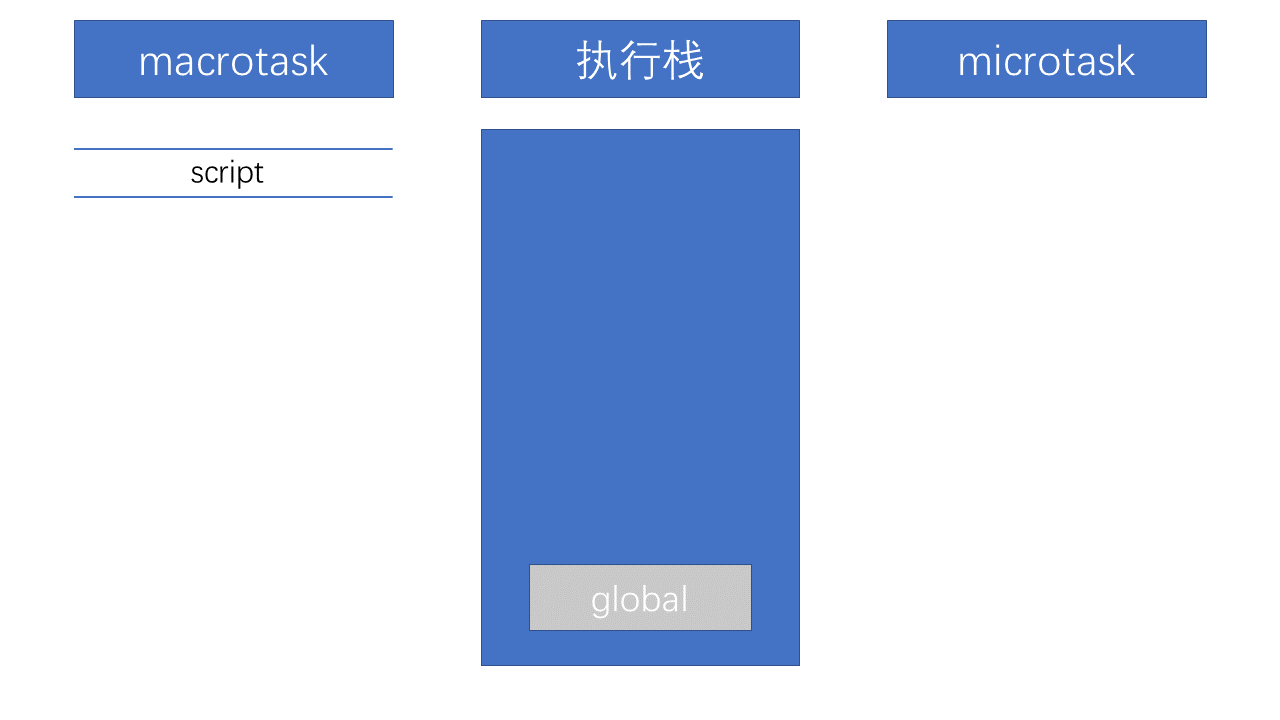
然后我们看到首先定义了两个async函数,接着往下看,然后遇到了 console 语句,直接输出 script start。输出之后,script 任务继续往下执行,遇到 setTimeout,其作为一个宏任务源,则会先将其任务分发到对应的队列中:

script 任务继续往下执行,执行了async1()函数,前面讲过async函数中在await之前的代码是立即执行的,所以会立即输出async1 start
遇到了await时,会将await后面的表达式执行一遍,所以就紧接着输出async2,然后将await后面的代码也就是console.log('async1 end')加入到microtask中的Promise队列中,接着跳出async1函数来执行后面的代码。

script任务继续往下执行,遇到Promise实例。由于Promise中的函数是立即执行的,而后续的 .then 则会被分发到 microtask 的 Promise队列中去。所以会先输出 promise1,然后执行 resolve,将 promise2 分配到对应队列。

script任务继续往下执行,最后只有一句输出了 script end,至此,全局任务就执行完毕了。
根据上述,每次执行完一个宏任务之后,会去检查是否存在 Microtasks;如果有,则执行 Microtasks 直至清空 Microtask Queue。
因而在script任务执行完毕之后,开始查找清空微任务队列。此时,微任务中, Promise 队列有的两个任务async1 end和promise2,因此按先后顺序输出 async1 end,promise2。当所有的 Microtasks 执行完毕之后,表示第一轮的循环就结束了。
变式一:
async function async1() {
console.log('async1 start');
await async2();
console.log('async1 end');
}
async function async2() {
//async2做出如下更改:
new Promise(function(resolve) {
console.log('promise1');
resolve();
}).then(function() {
console.log('promise2');
});
}
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0)
async1();
new Promise(function(resolve) {
console.log('promise3');
resolve();
}).then(function() {
console.log('promise4');
});
console.log('script end');
// script start
// async1 start
// promise1
// promise3
// script end
// promise2
// async1 end
// promise4
// setTimeout
变式二
async function async1() {
console.log('async1 start');
await async2();
//更改如下:
setTimeout(function() {
console.log('setTimeout1')
},0)
}
async function async2() {
//更改如下:
setTimeout(function() {
console.log('setTimeout2')
},0)
}
new Promise(function(resolve) {
console.log('promise2');
setTimeout(() => {
resolve();
}, 10)
console.log('promise2 resolve2')
}).then(function() {
console.log('promise3');
});
console.log('script start');
setTimeout(function() {
console.log('setTimeout3');
}, 0)
async1();
new Promise(function(resolve, reject) {
console.log('promise1');
reject();
console.log('promise1 resolve')
}).then(function() {
console.log('promise2');
}).catch(function(){
console.log('reject2');
});
console.log('script end');
// promise2
// promise2 resolve2
// script start
// async1 start
// promise1
// promise1 resolve
// script end
// reject2
// setTimeout3
// setTimeout2
// setTimeout1
// promise3
下面两段代码执行的结果一样,但是两段代码究竟有哪些不同呢?
var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f();
}
checkscope();
var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f;
}
checkscope()();
答案就是执行上下文栈的变化不一样
第一段代码:
ECStack.push(<checkscope> functionContext);
ECStack.push(<f> functionContext);
ECStack.pop();
ECStack.pop();
第一段代码:
ECStack.push(<checkscope> functionContext);
ECStack.pop();
ECStack.push(<f> functionContext);
ECStack.pop();
判断代码执行结果
function foo() {
console.log(a); // ncaught ReferenceError: a is not defined
a = 1;
}
foo(); // ???
function bar() {
a = 1;
console.log(a); // 1
}
bar();
TIP
setTimeout的延迟时间只是代表了消息被实际加入到队列的最小延迟时间,并不能表示实际的执行时间,具体什么时间执行还得根据这个队列在执行这个消息之前有没有其它消息
Promise中resove()或者reject()后的代码也会立即执行
# Javascript内存模式
JS内存空间分为栈(stack)、堆(heap)、池(一般也会归类为栈中)。 其中栈存放变量,堆存放复杂对象,池存放常量
# 基础数据类型与栈内存
JS中的基础数据类型,这些值都有固定的大小,往往都保存在栈内存中(闭包除外),由系统自动分配存储空间。我们可以直接操作保存在栈内存空间的值,因此基础数据类型都是按值访问,数据在栈内存中的存储与使用方式类似于数据结构中的堆栈数据结构,遵循后进先出的原则
# 引用数据类型与堆内存
JS的引用数据类型,比如数组Array,它们值的大小是不固定的。引用数据类型的值是保存在堆内存中的对象。JS不允许直接访问堆内存中的位置,因此我们不能直接操作对象的堆内存空间。在操作对象时,实际上是在操作对象的引用而不是实际的对象。因此,引用类型的值都是按引用访问的。这里的引用,我们可以粗浅地理解为保存在栈内存中的一个地址,该地址与堆内存的实际值相关联
# JavaScript 内存生命周期
JS环境中分配的内存一般有如下生命周期:
内存分配:当我们申明变量、函数、对象的时候,系统会自动为他们分配内存
内存使用:即读写内存,也就是使用变量、函数等
内存回收:使用完毕,由垃圾回收机制自动回收不再使用的内存
# JavaScript 的内存回收机制
JavaScript 的内存回收机制原理很简单,就是找出那些不再继续使用的值,然后释放其占用的内存。垃圾收集器会每隔固定的时间段就执行一次释放操作 主要有两种:引用计数垃圾收集和标记-清除算法
TIP
JS是单线程运行的,所以在进行垃圾回收工作的时候,其它的各种运行逻辑都会被暂停
# 引用计数垃圾收集
这是最初级的垃圾收集算法。此算法把“对象是否不再需要”简化定义为“对象有没有其他对象引用到它”。如果没有引用指向该对象(零引用),对象将被垃圾回收机制回收。
当声明了一个变量并将一个引用类型值赋给该变量时,刚这个值的引用次数就是 1 。如果同一个值又被赋值给另一个变量,则该值的引用次数加 1 。相反,如果引用这个值的变量重新赋值了另外一个值,则这个值的引用次数减1。当这个值的引用次数变成 0 时,则说明没有办法再访问这个值了,因而就可以将其占用的内存空间回收回来
var o = {
a: {
b:2
}
};
// 两个对象被创建,一个作为另一个的属性被引用,另一个被分配给变量o
// 很显然,没有一个可以被垃圾收集
var o2 = o; // o2变量是第二个对“这个对象”的引用
o = 1; // 现在,“这个对象”只有一个o2变量的引用了,“这个对象”的原始引用o已经没有
var oa = o2.a; // 引用“这个对象”的a属性
// 现在,“这个对象”有两个引用了,一个是o2,一个是oa
o2 = "yo"; // 虽然最初的对象现在已经是零引用了,可以被垃圾回收了
// 但是它的属性a的对象还在被oa引用,所以还不能回收
oa = null; // a属性的那个对象现在也是零引用了
// 它可以被垃圾回收了
引用计数的缺陷:循环引用
function f(){
var o = {};
var o2 = {};
o.a = o2; // o 引用 o2
o2.a = o; // o2 引用 o
return "azerty";
}
f();
两个对象被创建,并互相引用,形成了一个循环。它们被调用之后会离开函数作用域,所以它们已经没有用了,可以被回收了。然而,引用计数算法考虑到它们互相都有至少一次引用,所以它们不会被回收
# 标记-清除算法
这是当前主流的GC算法,V8 的回收机制就有用到这种方式。从字面上可以知道这种算法分 标记 与 清除 两个阶段
标记
标记就是通过从根(全局对象)位置开始,把能遍历到的内存中的对象标记为活动对象,标记完成之后还没被标记的对象就是非活动对象,这些非活动对象将会被清除
清除
清除阶段的遍历过程是从堆的首地址开始,一个个的遍历对象的标志位,将非活动对象清除
标记清除算法步骤如下:
GC维护一个root列表,root通常是代码中持有引用的全局变量。JS中,window对象就是一例作为root的全局变量。window对象一直存在,所以GC认为它及其所有孩子一直存在(非垃圾)
所有root都会被检查并标记为活跃(非垃圾),其所有孩子也被递归检查。能通过root访问到的所有东西都不会被当做垃圾
所有没被标记为活跃的内存块都被当做垃圾,GC可以把它们释放掉归还给操作系统
# GC复制算法
复制算法也叫Scavenge 算法,就是将堆中的所有活动对象复制到另外一个空间,然后原来的空间全部回收掉。这样的好处就是防止出现内存的碎片化,易于随后为程序分配新的空间
什么内存碎片化?
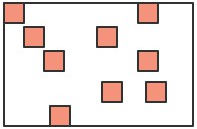
如上图所示深色的小方块代表存活对象,白色部分表示待分配的内存,由于堆内存是连续分配的,这样零零散散的空间可能会导致稍微大一点的对象没有办法进行空间分配,这种零散的空间也叫做内存碎片
Scavenge 算法主要就是解决内存碎片的问题,在进行一顿复制之后,To空间变成了这个样子:

# Chrome V8 的垃圾回收
以 Chrome 浏览器为例,它使用的哪种回收方式呢?
它使用的是多种回收算法的组合优化,而非某种单一算法。V8 的 GC 算法统称为分代垃圾回收算法,也就是通过记录对象的引用次数,将超过一定引用次数的对象划分为 老年对象,剩下的称之为 新生代对象,然后分别对他们采用不同到的垃圾回收算法。 对于新生对象采用复制算法,对于老生对象标记-清除算法,
那这样划分到底有什么优势呢,我们知道程序中生成的大多数对象其实都是产生之后随即丢弃。以下面代码为例,函数内部生成了对象,在该函数执行完毕,出栈之后,包括函数本身以及它内部的变量都会立刻成为垃圾:
// 该函数的执行上下文环境非全局作用域
function foo() {
var a = {c:1};
var c = {c:2};
}
那么对于这种新生代对象来说,回收就会变得很频繁,如果使用 GC 标记清除算法,那么就意味着每次清除过程需要处理很多的对象,会浪费大量的的时间。于是 V8 对新生代对象采用 GC 复制算法的方式,只需要将活动对象复制出来,然后将整个 From 清空即可,无需再去遍历需要清除的对象,达到优化的目的。
而针对老年对象则不同,它们都有多个引用,也就意味着它们成为非活动对象的概率较小,也就可以理解为老年对象不会轻易变成垃圾。再进一步也就是老对象产生的垃圾很少,如果采用复制算法的话得不偿失,大量的老年对象被复制来复制去也会增加负担,所以针对老年对象采用的是标记清除法,需要清除的老年对象只是少数,这样标记清除算法会更有优势
什么样的新生代对象会被晋升为老生代对象?
已经经历过一次 Scavenge 回收。
在进行复制算法时空间的内存占用超过25%
晋升过程?
在默认情况下,V8对新生代对象进行从From到To空间进行复制时,会先检查它的内存地址来判断这个对象是否已经经历过一次Scanvenge回收。如果已经经历过,那么会将该对象从From空间直接复制到老生代空间,如果没有,才会将其复制到To空间
# V8 内存限制
在其他的后端语言中,如Java/Go, 对于内存的使用没有什么限制,但是JS不一样,V8只能使用系统的一部分内存,具体来说,在64位系统下,V8最多只能分配1.4G, 在 32 位系统中,最多只能分配0.7G。你想想在前端这样的大内存需求其实并不大,但对于后端而言,nodejs 如果遇到一个2G多的文件,那么将无法全部将其读入内存进行各种操作了
V8 为什么要给它设置内存上限?明明我的机器大几十G的内存,只能让我用这么一点?
究其根本,是由两个因素所共同决定的,一个是JS单线程的执行机制,另一个是JS垃圾回收机制的限制
首先JS是单线程运行的,这意味着一旦进入到垃圾回收,那么其它的各种运行逻辑都要暂停
另一方面垃圾回收其实是非常耗时间的操作
因此为了避免应用性能和响应能力直线下降。因此,V8 做了一个简单粗暴的选择,那就是限制堆内存,也算是一种权衡的手段,因为大部分情况是不会遇到操作几个G内存这样的场景的
不过,如果你想调整这个内存的限制也不是不行。配置命令如下:
// 这是调整老生代这部分的内存,单位是MB。后面会详细介绍新生代和老生代内存
node --max-old-space-size=2048 xxx.js
// 这是调整新生代这部分的内存,单位是 KB。
node --max-new-space-size=2048 xxx.js
# 增量标记
由于JS的单线程机制,V8 在进行垃圾回收的时候,不可避免地会阻塞业务逻辑的执行,倘若老生代的垃圾回收任务很重,那么耗时会非常可怕,严重影响应用的性能。那这个时候为了避免这样问题,V8 采取了增量标记的方案,即将一口气完成的标记任务分为很多小的部分完成,每做完一个小的部分就”歇”一下,就js应用逻辑执行一会儿,然后再执行下面的部分,如果循环,直到标记阶段完成才进入内存碎片的整理上面来